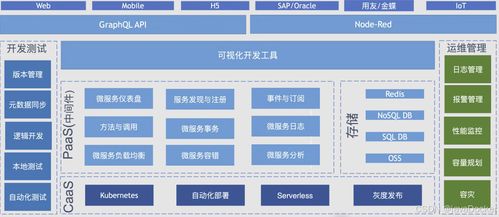
拆穿“超節點”偽裝 無內存統一編址,本質仍是服務器堆疊
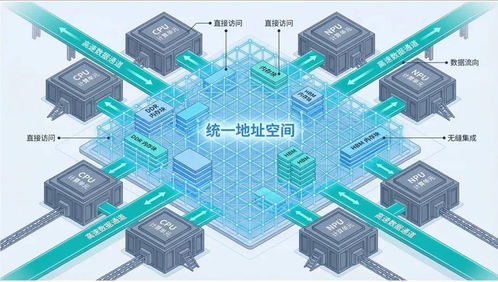
數據中心和云計算領域涌現出“超節點”(Hyper-Converged Node)等新概念,宣稱通過軟硬件深度集成,實現了前所未有的性能與效率飛躍。當我們深入技術內核,特別是剖析其內存架構與數據處理本質時,會發現許多所謂的“超節點”產品,不過是舊有“服務器堆疊”模式披上了一層新的外衣,其核心短板——缺乏真正的內存統一編址——使其難以兌現革命性的承諾。
讓我們澄清兩個核心概念:內存統一編址與服務器堆疊。
真正的內存統一編址(如UMA, Uniform Memory Access, 或在更大尺度上追求的“內存池化”或“內存分解”),旨在將集群中多個物理服務器的內存抽象為一個巨大的、連續的共享地址空間。應用程序可以直接、透明地訪問遠超單機容量的內存,無需復雜的數據遷移和拷貝,這能極大簡化編程模型,并顯著提升數據密集型應用(如大規模圖計算、實時分析、內存數據庫)的性能。這是邁向“一臺計算機”愿景的關鍵一步。
而服務器堆疊,本質上是通過高速網絡(如InfiniBand, RoCE)將多臺獨立的服務器連接起來,每臺服務器仍保有自己獨立的內存空間和操作系統。雖然可以通過軟件(如分布式共享內存系統、遠程直接內存訪問RDMA)實現跨節點的內存訪問,但這并非“統一編址”。數據訪問存在明顯的遠近之分(NUMA, Non-Uniform Memory Access擴展到集群級別),編程復雜,性能受網絡延遲和帶寬制約嚴重,本質上仍是分布式系統。
許多標榜為“超節點”的解決方案,其技術實質正是后者。它們可能將計算、存儲硬件封裝在一個機箱內,通過內部高速互聯(如PCIe Switch)提升了帶寬,降低了延遲,比傳統的通過網絡交換機連接的服務器集群更緊密。在內存架構上,并未實現根本性突破:
- 獨立內存空間:每個處理器或計算模塊仍然直接管理其本地內存。跨節點內存訪問需要通過特定的API(如基于RDMA)顯式進行,對應用不透明。
- 軟件棧復雜:為了模擬“統一”的體驗,需要復雜的中間件、驅動和虛擬機監控器(Hypervisor)來管理數據分布和訪問。這本身引入了開銷和復雜性。
- 擴展性局限:隨著節點增加,跨節點訪問的比例和延遲問題會線性或非線性增長,無法像真正統一內存系統那樣近乎線性擴展。
這種架構直接影響了其“數據處理和存儲支持服務”的能力:
- 數據處理瓶頸:對于需要頻繁隨機訪問大規模數據集的應用,跨節點內存訪問的網絡延遲(即使是微秒級)將成為關鍵瓶頸。數據處理引擎(如Spark、Flink)仍需精心設計數據分區和本地性策略,無法像使用單機大內存那樣自由。
- 存儲服務的本質:許多“超節點”強調其超融合特性,將存儲服務(如分布式存儲軟件)直接運行在每個計算節點上。這確實是服務器堆疊架構的典型應用——通過軟件定義存儲將各節點的本地磁盤聚合為統一存儲池。但這與內存統一編址是兩個不同層面的問題。其存儲性能的提升主要得益于更緊密的硬件集成和更快的內部互聯,而非內存架構的革命。
- 支持服務的效率:運行在之上的數據庫、緩存等中間件服務,若要實現極致性能,仍需感知底層節點拓撲,進行數據分片和副本放置優化,無法完全擺脫分布式系統的管理復雜度。
因此,當下許多“超節點”產品,可以視作是“高度集成化的、優化了內部互聯的服務器堆疊集群”。它比傳統分散式集群有優勢,但并未跨越到內存統一編址所代表的新范式。
真正的技術前沿正在朝打破“服務器”邊界、實現資源池化的方向努力,例如通過CXL(Compute Express Link)互聯協議構建真正共享的內存池,或通過新型硬件和操作系統支持實現內存的“分解”與按需分配。這些技術有望在未來重新定義“節點”的概念。
結論是,在評估“超節點”或任何集成化系統時,需穿透營銷術語,直擊其內存架構本質:是實現了透明的、統一編址的共享內存,還是僅僅提供了更快捷的遠程內存訪問通道? 對于后者,我們應理性視其為服務器堆疊技術的有益演進,它能解決許多特定場景下的性能與部署難題,但不應期待其帶來根本性的編程模型和適用性變革。在數據處理和存儲支持服務層面,它提供了更優的集成平臺,但并未消除分布式系統固有的挑戰。拆開其“偽裝”,有助于我們做出更貼合實際需求的技術選型與架構規劃。
如若轉載,請注明出處:http://www.spacom.cn/product/21.html
更新時間:2026-06-15 02:49:25